WRF
傻逼Fortran,2021年了,居然还有人用Fortran
最好找做气象的人问问有关参数设置的问题,可惜我没找到
这是一个有关地球科学的天气模拟系统,所有有关地球科学和Fortran并行化的其他应用都可以参考一下
Task links and introductions
3 Domain Problem for ISC21 SCC
Install
required libs
HDF5, NetCDF-C, NetCDF-Fortran (手动安装可能更好,需要mpi)
HDF5
./configure --prefix=你的安装路径/hdf5 --enable-fortran --enable-fortran2003 --enable-parallel
make -j 48
make install
# vi ~/.bashrc
export HDF5=你的安装路径/hdf5
export PATH=$HDF5/bin:$PATH
export LD_LIBRARY_PATH=$HDF5/lib:$LD_LIBRARY_PATH
export INCLUDE=$HDF5/include:$INCLUDE
# source ~/.bashrc
NetCDF-C
./configure --prefix=你的安装路径/netcdf LDFLAGS="-L$HDF5/lib" CPPFLAGS="-I$HDF5/include" CC=mpiicc --disable-dap
make -j 48
make install
# vi ~/.bashrc
export NETCDF=/usr/local/netcdf
export PATH=$NETCDF/bin:$PATH
export LD_LIBRARY_PATH=$NETCDF/lib:$LD_LIBRARY_PATH
export INCLUDE=$NETCDF/include:$INCLUDE
# source ~/.bashrc
NetCDF-Fortran
./configure --prefix=你的安装路径/netcdf CPPFLAGS="-I$HDF5/include -I$NETCDF/include" LDFLAGS="-L$HDF5/lib -L$NETCDF/lib" CC=mpiicc FC=mpiif90 F77=mpiif90 # 与NetCDF-C安装在同一目录下
make -j 48
make install
Advanced lib
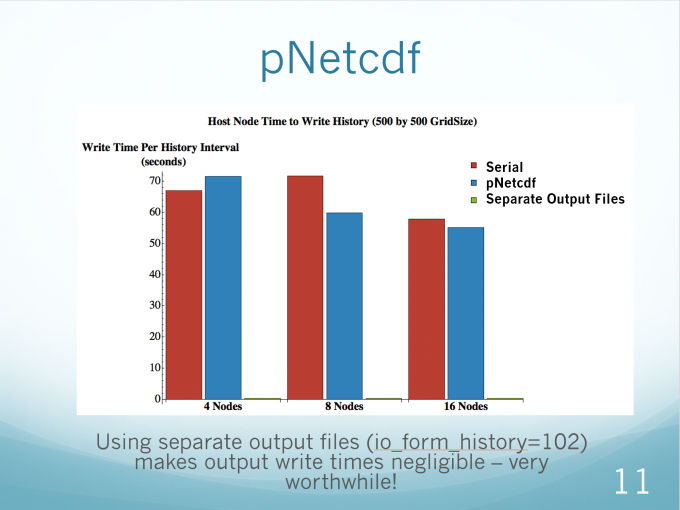
PNetCDF A Parallel I/O Library for NetCDF File Access
4个node有负面效果,需要8个node及以上才会和NertCDF有异
{kind=link}
安装方法见官网
Main Program
经过测试,使用intelMPI会出现segment fault,OpenMPI则不会,然而intelMPI好像并没有很多提高,可以从stack size的角度尝试修正这个问题。
env setting
intel openmpi hdf5 netcdf
config and build
./configure
checking for perl5... no
checking for perl... found /usr/bin/perl (perl)
Will use NETCDF in dir: /global/software/centos-7.x86_64/modules/intel/2020.1.217/netcdf/4.7.4
HDF5 not set in environment. Will configure WRF for use without.
PHDF5 not set in environment. Will configure WRF for use without.
Will use 'time' to report timing information
$JASPERLIB or $JASPERINC not found in environment, configuring to build without grib2 I/O...
------------------------------------------------------------------------
Please select from among the following Linux x86_64 options:
1. (serial) 2. (smpar) 3. (dmpar) 4. (dm+sm) PGI (pgf90/gcc)
5. (serial) 6. (smpar) 7. (dmpar) 8. (dm+sm) PGI (pgf90/pgcc): SGI MPT
9. (serial) 10. (smpar) 11. (dmpar) 12. (dm+sm) PGI (pgf90/gcc): PGI accelerator
13. (serial) 14. (smpar) 15. (dmpar) 16. (dm+sm) INTEL (ifort/icc)
17. (dm+sm) INTEL (ifort/icc): Xeon Phi (MIC architecture)
18. (serial) 19. (smpar) 20. (dmpar) 21. (dm+sm) INTEL (ifort/icc): Xeon (SNB with AVX mods)
22. (serial) 23. (smpar) 24. (dmpar) 25. (dm+sm) INTEL (ifort/icc): SGI MPT
26. (serial) 27. (smpar) 28. (dmpar) 29. (dm+sm) INTEL (ifort/icc): IBM POE
30. (serial) 31. (dmpar) PATHSCALE (pathf90/pathcc)
32. (serial) 33. (smpar) 34. (dmpar) 35. (dm+sm) GNU (gfortran/gcc)
36. (serial) 37. (smpar) 38. (dmpar) 39. (dm+sm) IBM (xlf90_r/cc_r)
40. (serial) 41. (smpar) 42. (dmpar) 43. (dm+sm) PGI (ftn/gcc): Cray XC CLE
44. (serial) 45. (smpar) 46. (dmpar) 47. (dm+sm) CRAY CCE (ftn $(NOOMP)/cc): Cray XE and XC
48. (serial) 49. (smpar) 50. (dmpar) 51. (dm+sm) INTEL (ftn/icc): Cray XC
52. (serial) 53. (smpar) 54. (dmpar) 55. (dm+sm) PGI (pgf90/pgcc)
56. (serial) 57. (smpar) 58. (dmpar) 59. (dm+sm) PGI (pgf90/gcc): -f90=pgf90
60. (serial) 61. (smpar) 62. (dmpar) 63. (dm+sm) PGI (pgf90/pgcc): -f90=pgf90
64. (serial) 65. (smpar) 66. (dmpar) 67. (dm+sm) INTEL (ifort/icc): HSW/BDW
68. (serial) 69. (smpar) 70. (dmpar) 71. (dm+sm) INTEL (ifort/icc): KNL MIC
72. (serial) 73. (smpar) 74. (dmpar) 75. (dm+sm) FUJITSU (frtpx/fccpx): FX10/FX100 SPARC64 IXfx/Xlfx
Enter selection [1-75] :
dm+sm: OMP+MPI
./compile -j 6 em_real >& build_wrf.log
tail -15 build_wrf.log
finish
所有执行文件都在run文件夹中。
Run
for i in ../WRF/run/* ; do ln -sf $i $(数据所在目录) ; done
namelist.input是输入文件,其中有众多参数需要设置,可以参考WRF NAMELIST.INPUT FILE DESCRIPTION。
slurm script
#!/bin/bash -l
#SBATCH -N 4
#SBATCH --ntasks-per-node=20
#SBATCH --cpus-per-task=2
#SBATCH --ntasks=80
#SBATCH -J wrf3Dom_mpi_80_omp_2
#SBATCH -p compute
#SBATCH -t 2:00:00
#SBATCH -o wrf3Dom-%j.out
sleep 300
module load NiaEnv/2019b
module load intel/2019u4 openmpi/4.0.1
#hdf5/1.10.5
#module load netcdf/4.6.3
ulimit -c unlimited
ulimit -s unlimited
module list
export HDF5=/home/l/lcl_uotiscscc/lcl_uotiscsccs1034/scratch/nonspack/hdf5
export PATH=$HDF5/bin:$PATH
export LD_LIBRARY_PATH=$HDF5/lib:$LD_LIBRARY_PATH
export INCLUDE=$HDF5/include:$INCLUDE
export NETCDF=/home/l/lcl_uotiscscc/lcl_uotiscsccs1034/scratch/nonspack/netcdf
export PATH=$NETCDF/bin:$PATH
export LD_LIBRARY_PATH=$NETCDF/lib:$LD_LIBRARY_PATH
export INCLUDE=$NETCDF/include:$INCLUDE
export KMP_STACKSIZE=20480000000
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
cd ~/scratch/pl/orifiles
mpirun -np 80 -cpus-per-rank $SLURM_CPUS_PER_TASK ./wrf.exe
Important Notice
stack size and segment fault
ulimit sets the OS limits for the program.
KMP_STACKSIZE tells the OpenMP implementation about how much stack to actually allocate for each of the stacks. So, depending on your OS defaults you might need both. BTW, you should rather use OMP_STACKSIZE instead, as KMP_STACKSIZE is the environment variable used by the Intel and clang compilers. OMP_STACKSIZE is the standard way of setting the stack size of the OpenMP threads.
Note, that this problem is usually more exposed, as Fortran tends to keep more data on the stack, esp. arrays. Some compilers can move such arrays to the heap automatically, see for instance -heap-arrays for the Intel compiler.
Fortran的OMP进程会在stack里塞一大堆东西,很多时候会爆栈,所以使用Fortran和OMP的应用需要注意export KMP_STACKSIZE=20480000000, 而且gcc是OMP,icc是KMP。
Fortran and MPI
不知道是slurm还是Fortran的问题,slurm不能对Fortran的MPI程序自动分配CPU核心,所以需要手动设置,
mpirun -np 16 -cpus-per-rank $SLURM_CPUS_PER_TASK ./wrf.exe
tell mpi how many cpu cores should one mpi rank get for openmp
IPM Report env setting
IPM是一个监控MPI使用的profiler。使用IPM只需要perloadIPM的lib就可以了。但是为了完整生成报告图片,需要设定以下变量
export IPM_REPORT=full
export IPM_LOG=full
When using IPM, set above envs to make sure you can get right xml to visualize, or using https://files.slack.com/files-pri/TAXMW9014-F02586VN27L/download/ipm.ipynb to visualize